This release is a significant milestone in the development of the emulator. We have bumped the release level from 0.20 to 1.00 as we feel the emulator is now functionally complete. It is not finished, of course, and probably never will be. There are features of the B5500 that we still do not support (e.g., drums and paper tape devices), areas where significant improvements can be made (e.g., multiple datacom stations), and some areas that may not be practical to support in a browser-based emulator (e.g., File Protect Memory, shared disk systems, and additional datacom line-adapter types). Those issues can be pursued as our time and the desire of the user community permit.
This is also a very large release, with many new features and changes to existing ones. This blog post will attempt to introduce and summarize these changes, but there have been extensive updates to the wiki pages as well. The wiki now also has a table of contents, which can be displayed as a sidebar on the left of the wiki pages. We recommend that before using this new release, you peruse the following wiki pages in particular:
New System Configuration Mechanism
The most significant feature of this release is a completely new, and much more flexible configuration mechanism for the emulator.
Overview
In earlier releases, the system configuration was defined by a static Javascript file, emulator/B5500SystemConfiguration.js. If you were running your own web server, you could modify this file to alter the system configuration -- the processors, memory modules, I/O control units, and peripheral devices the emulator would use. If you were using the emulator from a web server hosted by someone else, however, you were stuck with whatever configuration was coded in the Javascript file on that server.
An additional restriction in earlier releases was that the configuration of the disk subsystem was fixed by the B5500ColdLoader.html script and could not be changed. The standard script created a disk subsystem with two Electronics Units (EUs) having a total of 400,000 sectors, or 96 million 6-bit characters of storage.
The new mechanism stores the system configuration in a small IndexedDB database within your browser. There is a new user interface (UI) that allows you to select the system components you want to make up a configuration. Since this data is stored locally on your workstation, each user can control their own configuration, even when the emulator files are hosted on an external web server. The Javascript file still exists, but its role is now to define the structure of the system configuration data. It is no longer used by the running emulator.
You can now also define multiple configurations and easily switch among them. Each configuration has a name that identifies it within the IndexedDB database. There is no practical limit to the number of configurations you can create. Switching between configurations is as easy as opening the configuration UI and selecting the desired name from a pull-down list.
In addition, the new configuration mechanism supports multiple disk subsystems. Each disk subsystem is implemented as a separate IndexedDB database within the browser. There are a number of uses for multiple disk subsystems. One is to support separate systems for the Datacom and Timesharing MCPs. Another is to maintain different levels of the MCP and easily switch among them.
You can specify the number of EUs in a disk subsystem and the number of Storage Units (SUs) independently for each EU. You can also modify the configuration of a subsystem at a later time to add more EUs or add more SUs to existing EUs. A disk subsystem can have up to 20 EUs (the B5500 maximum), although only the first ten EUs are addressable when the system configuration includes a Disk File Exchange (DFX) component.
The emulator now supports both the original Model-I SUs (40,000 sectors, 20ms average access time) and Model-IB SUs (80,000 sectors, 40ms average access time). The latter model was known as "bulk" or "slow" disk. All SUs for an EU must be the same model, but separate EUs can have different SU models.
You assign a name to each disk subsystem when you create it. That name also becomes the name of the subsystem's IndexedDB database. You use this name to assign the subsystem to a system configuration. A given system configuration can have only one disk subsystem associated with it at a time, but the subsystem associated with a system configuration can be changed at any time.
Using the New Configuration Interface
The emulator permits configuration changes to be made only when it is in a powered-off state. To access the configuration UI, simply click the "B5500" logo (below the Burroughs logo) on the right side of the Operator Console window. A System Configuration sub-window will open:
 |
| Emulator System Configuration Dialog |
To change the set of components in a configuration, simply tick or un-tick the appropriate check boxes on the dialog and click the SAVE button. To switch to a different configuration, select it from the Configuration name list and click SAVE. To create a new system configuration, click the NEW button. The dialog will prompt you for the name of the new configuration and then fill the dialog with a default configuration, which you can modify as desired. Each time you click the SAVE button, the displayed configuration becomes the "current" configuration for the emulator. That will be the one used the next time the emulator is powered-on.
To delete a configuration, select its name from the pull-down list and click the DELETE button. The dialog will prompt you for confirmation of the delete, but once acknowledged, the deletion is permanent and cannot be undone.
Note that some elements on this dialog represent features that are not presently supported by the emulator. Their controls are disabled on the dialog.
You assign a disk subsystem to a system configuration by selecting the subsystem name from the Storage name pull-down list on the dialog. Saving the configuration associates that subsystem with that configuration. You can create or modify a disk subsystem by clicking the NEW or EDIT buttons next to the list of storage names. Doing so will open the Disk Storage Configuration dialog in a new sub-window:
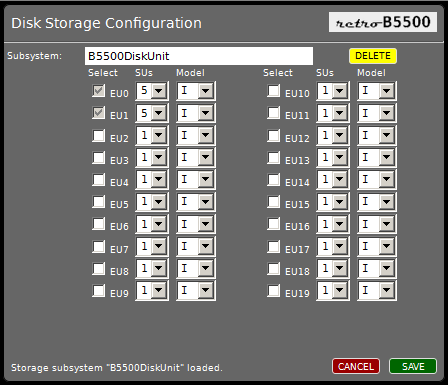 |
| Disk Storage Configuration Dialog |
If you click the NEW button, the system configuration dialog will prompt you for the name of the new disk subsystem before opening the storage configuration dialog. To add EUs to the subsystem, simply tick their check boxes and select the number and model of SUs the EU should have. Click the SAVE button on this dialog to update the configuration, apply any necessary schema changes to the IndexedDB database, and associate this subsystem with the underlying system configuration.
Once you click SAVE, any storage you have added to the subsystem becomes a permanent part of the subsystem and cannot be removed later. The check boxes for the selected EUs will be disabled so that they cannot be un-ticked. You may not decrease the number of SUs, nor change Model-IB SUs to Model-I SUs, as either of those changes would reduce the amount of storage in the subsystem.
The reason for the restriction on removing storage from a subsystem is that the B5500 MCP considers all disk on the system to be a monolithic resource. Disk files are organized as a set of separately-allocated areas (extents), which may be spread across multiple EUs of the subsystem. Removing storage from the subsystem could cause some areas of files to disappear, so the emulator does not allow this.
To delete a disk subsystem, open it in the Storage Configuration dialog and click the DELETE button. The dialog will prompt you for confirmation, but once acknowledged, the IndexedDB database for the subsystem will be deleted from your workstation. This deletion cannot be undone.
Disk subsystems from earlier emulator releases can be used without change in 1.00 and later releases. These legacy subsystems have the name B5500DiskUnit. The legacy subsystems can continue to be used with earlier releases of the emulator if their configuration is not changed. Once you change the configuration of a disk subsystem, however, it can no longer be used by releases prior to 1.00. There two reasons for this:
- Adding EUs to a disk subsystem requires a change to the IndexedDB database schema. This change increases the IndexedDB version property for the database. Releases prior to 1.00 required the database to be at version 1 and will not open a database having a higher version.
- Each IndexedDB database for a disk subsystem contains a configuration table that describes the EUs in the subsystem. The format of that configuration table has changed for release 1.00 in a way that is incompatible with earlier releases. This also means that disk subsystems created by release 1.00 and later cannot be used with earlier emulator releases, even it their IndexedDB version is 1.
Updating from Earlier Releases
When you first power-on the 1.00 emulator in a browser with which the emulator was previously used, the emulator will create a default system configuration named "Default", having a set of components that is somewhat reduced from the default configuration in earlier releases. In particular, it has only one Disk File Control Unit (DKA) and one magnetic tape drive. The configuration will include any existing legacy B5500DiskUnit subsystem. You may wish to adjust this default configuration before proceeding further.
When you first power-on the 1.00 emulator in a browser where the emulator has not been previously used, the emulator will create both the default system configuration described above and a default disk subsystem named B5500DiskUnit. That configuration will have half the storage of previous default configurations -- one EU with 200,000 sectors, or 48 million characters.
Please see the Configuring the System wiki page for more details on the new configuration mechanism and how to use it.
New Cold Start Process
With the implementation of the new system configuration mechanism in this release, use of the B5500ColdLoader.html script is now deprecated. That script served to create the IndexedDB disk subsystem, initialize the disk directory structures, establish the bootstrap mechanism, and load the MCP and other system files from ".bcd" tape images. It dates from a very early point in the emulator development, long before card reader and magnetic tape peripheral devices were implemented.
We now recommend that disk subsystems be created using the new system configuration mechanism, and that they be initialized the old-fashioned way -- with a Cold Start card deck.
We have actually been able to Cold Start the system from a card deck for almost a year, ever since the initial tape drive implementation was made available in release 0.15 last November. We owe thanks to Tim Sirianni and Paul Cumberworth for pioneering the research in how to do this, using the ESPOL compiler to generate the necessary card-load decks from relevant symbol files, and assembling the decks with an appropriate set of parameter cards.
I have taken Tim's latest version of his deck, reworked the parameter cards somewhat, and created a default Cold Start deck you can load directly, or use as a base for customization. This deck is in the tools/ directory of the emulator files, and can also be downloaded from our hosting site at http://www.phkimpel.us/B5500/tools/COLDSTART-XIII.card.
The Cold Start deck consists of two "card-load-select" programs, the COLD Loader and Tape-to-Disk Loader, along with their respective control cards. At the end of the deck is a short MCP Library/Maintenance job that will load a minimal set of system files from the Mark-XIII SYSTEM tape image to disk.
To use the Cold Start deck, follow these steps:
- First download a copy of the deck to your local file system.
- If you wish, you can modify the parameter cards to suit your preferences, but be careful not to disturb the card images for the card-load programs themselves. Many of the settings on the parameter cards can be modified using SPO commands after the MCP is up and running, so you may want to leave the deck as is, at least initially.
- Load the emulator into your browser. Make sure you have the correct system configuration and disk subsystem selected. A Cold Start wipes out any existing disk directory on the disk subsystem, effectively destroying all B5500 files in the subsystem.
- Power-on the emulator.
- Load the Cold Start deck into card reader CRA and press the START button on the reader.
- Load the SYSTEM tape image into a tape drive (any available drive will do) and click the drive's REMOTE button to make it ready.
- On the Operator Console, click the yellow CARD LOAD SELECT button so that it illuminates.
- Click the LOAD button on the Console. The reader will load the one-card binary bootstrap on the front of the deck, which will then load the COLD Loader program into memory and start executing it. The COLD Loader will initialize the disk subsystem and create an empty disk directory. It will also process the parameter cards and store their values on disk. The program will then print "DIRECTRY BUILT" [sic] on the SPO and halt. The process should take about 30 seconds.
- Leave the CARD LOAD SELECT button illuminated. Click the HALT button, then click LOAD again. The reader will load another one-card binary bootstrap, which will in turn load the Tape-to-Disk Loader program and start executing it. You should see the tape spin as the loader searches for the MCP file and loads it to disk. After a successful load, the program will print "MCP FILE LOADED" on the SPO. It will then automatically boot the MCP just loaded.
- The standard parameter cards for the COLD Loader will set an MCP option that requires you to set the time of day after a halt/load. You should first set the date with the SPO DR command. Then once you set the time with a TR command, the MCP will read the cards for the Library/Maintenance job and load those files to disk.
- One of the files that job loads is the System Intrinsics, INT/DISK. Since the system was just Cold Started, you must specify the name of the Intrinsics file to the MCP using the SPO command "CI INT/DISK". The MCP will preserve that setting across future halt/loads.
- At this point the system is fully initialized and ready for use. You may wish to load additional files from the SYSTEM tape, or wait and load more files later as the need arises. It would be a good idea to click the CARD LOAD SELECT button at this time to turn it off.
The B5500ColdLoader.html script can still be used to initialize a disk subsystem for use with release 1.00, but it can only work with the disk subsystem named B5500DiskUnit in its legacy configuration. This script will be removed in a future release, so we strongly recommend that you stop using that script and switch to the new process described above.
Please see the Getting Started wiki page for more details on how to initialize the emulator environment using the new configuration mechanism and Cold Start card deck. That page also has links to the B5500 reference manuals that describe the card-load-select programs and their parameter cards.
Off-line Emulator Operation and the "Application Cache"
The emulator, like most non-trivial web applications, cannot be loaded into a browser from your local file system. Instead, it must be loaded over HTTP from a web server. Once loaded, however, the emulator runs completely within the browser, and the web server is not needed again until the next time you load or reload the emulator.
The continually-evolving HTML5 standards have established a browser feature known as the "Application Cache." This is a bit of a misnomer, as it is not so much a cache as it is a way to install a web application within a browser for off-line use. Once the application is installed, it can be run in the browser without access to the web server from which it is hosted, and even without the browser having access to a network connection at all. Both Google Chrome and Mozilla Firefox support this capability.
Not all web applications can take advantage of off-line operation, especially if they require access to Internet resources while they are running. It is perfectly suited to the emulator, however, since the emulator requires no network or Internet access once it is loaded into the browser. Thus, it is now possible to use a version of the emulator that is hosted on an external web server in situations where you have no access to that server. You load the emulator into the browser using the same URL you would if operating on-line, but the browser will load the emulator files from its local Application Cache rather than from the web server.
Installation and use of the emulator from the Application Cache is unconditional and completely automatic. The first time you load the emulator using release 1.00 or later, the browser will load the emulator files into its local storage. You will see messages displayed in the top-left of the Operator Console window as the application is installed and the complete set of emulator files is downloaded.
Once the emulator is installed within your browser in this way, it will continue to be served from the local Application Cache, even when your browser has network access and can reach the web server from which the emulator was originally hosted. Instead of loading the emulator files from the server when on-line, the browser will instead check the server to see if a newer version of the emulator is available. This check takes place asynchronously, in the background, and neither inhibits nor delays use of the emulator while it is taking place. You will see some messages display in the top-left of the Console while this check takes place.
If a newer version of the emulator is available on the server, the browser will download it, again asynchronously in the background. The new version will be installed automatically in the Application Cache, but the browser will continue to use the prior version until the next time the emulator is reloaded in the browser. At that point the new version of the emulator will be used by the browser and the prior version will no longer be available. This behavior is not unlike the way that most web browsers themselves are updated automatically from the Internet and made available the next time you restart them on your workstation.
Please see the Using the Operator Console wiki page for more details on off-line operation of the emulator and the messages that are displayed during the application installation and update process.
Peripheral I/O Device Changes
This release contains numerous changes and enhancements to the I/O devices and their user interfaces. The following discussion summarizes the differences from prior releases, but please see the respective wiki page on each device for details.
Line Printer
The line printer driver has been completely rewritten. The original driver was a quick-and-dirty implementation, literally thrown together as a debugging exercise. It worked well enough that we have continued to use it, but it had no operating controls and was missing several important features.
The new driver supports a user interface with controls similar to those of the B329 printer. There are now buttons to make the printer ready and not ready, and to manually perform single-space and form-feed operations. To keep printed output from flooding the memory of the browser, the printer has long limited the capacity of its "paper" area to 150,000 lines -- about the equivalent of a box of the pin-feed forms used with the real printers. The new driver now supports an end-of-paper indicator and a more realistic way of clearing the "paper" from the printer when its capacity is reached.
The B5500 used five special Algol characters that do not have ASCII equivalents -- left-arrow, multiplication, not-equal, less-than-or-equal, and greater-than-or-equal. As described in the wiki pages, we have assigned ASCII substitutes for these (e.g., left-arrow as "~"), but several people have expressed a desire to see the actual Algol glyphs, especially in printer output.
The Unicode standard has glyphs for all five special Algol characters, and many fonts available for workstation operating systems include these glyphs. The new line printer driver will now generate these Unicode glyphs, but an option on the printer UI allows you to turn this off and still obtain printed output with the ASCII substitute characters. The default setting for that option can be specified in the system configuration.
Card Reader
The card reader will now unconditionally accept the five Unicode code points for the special Algol characters in "deck" files that are loaded into it. Files may contain a mixture of both Unicode and the ASCII substitutions for the Algol characters. The reader will now also accept the underscore ("_") as an ASCII substitute for the left-arrow.
Card Punch
Similar to the new line-printer driver, the card punch will now optionally output the five special Algol characters using Unicode glyphs. The default setting for that option is also in the system configuration.
The card punch UI now has annunciators on the right side of its panel that will illuminate when one of the output stackers reaches its capacity of 850 cards.
SPO
The SPO interface has been redesigned to accept keyboard input using a standard HTML text box. Formerly, keystrokes were simply captured by the driver when the SPO window or its paper area had the focus. This works fine when you have a real keyboard, but not at all on mobile devices such as tablets that simulate a keyboard on their touch surface. Most of these devices only display the simulated keyboard in a browser when the focus is in a text box or other control that accepts text input. Since the original SPO did not use a text control, there was no way to get the keyboard to appear.
In the new implementation, the SPO driver will enable a border-less, yellow-shaded text box at the bottom of the paper area whenever an I/O Control Unit issues a read operation to the SPO. The MCP initiates a SPO read in response to you clicking the INPUT REQUEST button on the SPO window, or pressing the ESC key when the SPO window has the focus. This text box is disabled and made invisible when you end input to the SPO.
This new approach has solved several obscure, but long-standing problems with input to the SPO. It also has the advantage that you now see a cursor when keying text on the SPO, and you can use standard GUI editing and copy/paste operations during SPO input. It seems to work fine on the tablets we have tested. There are still numerous issues with running the emulator on a mobile device, however (e.g., the I/O devices open as tabs instead of windows), but we have seen significant improvement during the past few months in the ability of mobile devices to support the emulator, particularly with Google Chrome on Android devices.
As a part of the changes to implement the new text input mechanism, the paper area of the SPO is no longer implemented as an HTML <iframe> element. You can still select and copy portions of the SPO output with your pointing device, but as a consequence of this change, it is no longer possible to save or print the contents of the paper area directly from your browser. To help compensate for this, double-clicking anywhere in the paper area will cause a new window to be opened and the current contents of the paper area copied into it. You can then save or print the SPO output from this separate window. Simply close the window when you are finished with it.
The amount of scroll-back retained by the SPO remains at 1500 lines. Older lines are discarded once this limit is reached.
Additional enhancements to the SPO include:
- Support for the Unicode Algol Glyphs on output has been implemented in a manner similar to that for the line printer and card punch. Unicode code points on input are not currently supported, however.
- The underscore ("_") is now accepted as a substitute for "~" on input. Keying either of these characters acts as if the END OF MESSAGE button had been clicked.
- When you resize the SPO window, the paper area will resize in concert. This is especially useful when running the emulator on a workstation with a relatively small screen. Below a certain minimum size, however, the paper area will no longer resize and the contents of the window will be clipped. The really interesting thing to me about this feature is that it was implemented entirely through CSS style sheet changes. No Javascript was harmed in the process.
Magnetic Tape
The tape loader window that is activated by clicking the LOAD button for a tape drive is now opened on top of the drive window. Previously it was opened in the center of the workstation screen, which could make it confusing to which drive the loader window applied.
Timing for the animation of the tape reel image on the drive window is now done at a more granular level. This should improve the quality of the animation and reduce the degree of visual beating between the simulated rotation of the reel and the screen refresh rate.
Disk
Disk devices do not have a user interface, but there have been a few significant improvements internally.
- The driver has been updated to work with the new system configuration and disk subsystem mechanism. It now attaches to the IndexedDB database for the disk subsystem specified by the current system configuration and adapts to the configuration of that subsystem.
- The driver now supports Model-IB (slow) disks in addition to the original Model-I disks, including the difference in average access time.
- The driver now supports both configurations with a Disk File Exchange (DFX) and those without a DFX. Without a DFX, the B5500 supports up to 20 EUs, with EU0-9 addressed by DKA and EU10-19 addressed by DKB. With the DFX enabled, the system can support only EU0-9, but both disk controls can address any disk.
- The emulator will now refuse to do a disk load if DKA is not selected in the system configuration. This mimics the way the B5500 hardware worked.
Datacom
The way that keyboard input for the datacom terminal was handled has been extensively reworked for better compatibility with Google Chrome. A more tablet-friendly input mechanism, similar to that described above for the SPO, is under consideration, but it is much more difficult to implement for a datacom terminal, as the input mode is initiated by the user pressing any key, not by the I/O Control Unit.
General Improvements
In earlier releases, the NOT READY indicators on the I/O device windows were rendered in red. Closer inspection of some color photographs of actual B5500 installations has revealed that this is incorrect -- the lamps were white. All I/O device windows have been updated to reflect this.
Several device windows have progress bars on them to indicate things such as input or output capacity. These were being rendered with HTML <progress> elements, but this usage is an incorrect application of that type of element. These have been converted to <meter> elements, which are visually very similar.
As with the resizing feature for the SPO, most other device drivers now resize their widow contents when their windows are resized.
Other Changes and Enhancements
Flag Bit Errors
For some time we have had a problem with programs aborting due to Flag Bit interrupts. These typically occur during periods of intense system activity, which suggests the problem may be related to Presence Bit interrupts. It has been a difficult problem to track down.
More or less by accident, I discovered a bug in the Processor object, where the stack was not being properly adjusted during the indexing of a descriptor. The value of the A register was being used without assuring first that the AROF validity flip-flop was set. As part of that, I also reworked portions of the OPDC and DESC operators in the area that detects Flag Bit errors.
Improper stack adjustment could lead to Flag Bit errors. These changes appear to have reduced the incidence of Flag Bit errors when the system is very busy, but they still occur occasionally. The most recent cases I've examined appear to happen during procedure exit, where the processor is checking the Flag Bit [0:1] on the Return Control Word. This is the only known bug in the Processor at present, and remains an outstanding issue (#23 in the project's issue list).
Downloadable Web Fonts
Normally, web browsers render the contents of their windows using fonts that are installed locally on the workstation. Browsers have for some time supported downloadable fonts, however, so we have taken advantage of that feature in this release. The intent is to standardize the fonts used by the emulator, and to eliminate any dependency on fonts installed locally on the workstation.
We have chosen the open-source DejaVu Sans and DejaVu Sans Mono fonts for use with the emulator. The Mono font was specifically chosen because it supports the Unicode glyphs for the special Algol characters, and because it has a numeric "0" glyph that is clearly distinguished from the letter "O".
This release includes files for these two fonts in both Web Font (.woff) and TrueType (.ttf) formats. The font files are quite large, but due to their local storage by the Application Cache feature discussed above, and the fact that they never change, you should be burdened by their download only once.
Operator Console Improvements
Prior to this release the NOT READY lamp on the Console was not implemented. When the emulator is powered-on, this lamp will now be illuminated if certain minimum configuration requirements are not met, e.g., no Processor is enabled in the configuration, the selection for P1 (the control processor) is not valid, or memory module 0 is not enabled. This is not exactly how that lamp behaved on the B5500, but the current implementation follows its purpose in spirit.
In previous releases, clicking the NOT READY lamp would toggle Processor B into or out of the running configuration. That was always intended as a temporary feature, and it has been removed in this release. The presence of PB can now be controlled through the new system configuration mechanism.
The Console will now perform a brief lamp test when the POWER ON button is clicked. Please report any burned out lamps on the forum.
The names of the current system configuration and disk subsystem are now displayed in the top-right of the Console window when the Console is in "non-purist" mode. Clicking the Burroughs logo toggles the Console between the historically-accurate "purist" mode and the default "non-purist" mode, which shows additional legends and annunciators for system status.
Miscellaneous Changes
Many of the scripts and style sheets have been significantly cleaned up and refactored. The user interface now has a more standardized appearance, and this will be easier to maintain going forward.
Images and fonts have been moved into a new webUI/resources/ directory to separate them from the HTML, CSS and Javascript files in webUI/. A number of files in the webUI/tool/, tools/, tests/, and source/ directories have been moved to more logical locations within the project's Subversion repository.
All HTML <meta> Content-Type character sets have been changed from ISO-8859-1 to UTF-8 so that the Unicode glyphs could be supported. A problem with FireFox requiring the character set to be specified within the first 1024 characters of an HTML file has been corrected.
Looking Forward
We have a few ideas for further enhancements in the emulator, but none of them is particularly urgent. Of course, it is likely that we will uncover more bugs that will need to be corrected, but except for the problem with occasional Flag Bit errors, the emulator at present seems to be quite robust and reliable.
The focus on future work is likely to be acquisition and restoration of more software for the B5500. We already have quite a bit that exists in the form of scanned listings. Those need to be transcribed, proofed, and debugged in order to make them useful. That is a very labor-intensive and frustrating process, but Jim Fehlinger has made amazing progress in the past several months with an OCR-based technique that has improved the throughput and reliability of the transcription process substantially, although it is still quite labor-intensive.
Development of the emulator itself has been a closely-held project, but restoration of software is something in which anyone (and everyone) can easily participate. Nigel and I have been pleasantly surprised by the amount of interest this project has garnered, especially given that we have not done all that much to advertise it. We hope that people will continue to be interested in and volunteer to work towards the restoration of software for this very interesting system.
The 50th anniversary of first customer shipment of the B5500 will occur in February 2015. There needs to be a party.

